
Yona Research: Immersion in the DA in SVM World


- Introduction: The Growing Need for DA Layers for Solana
- Why It’s Important to Develop an SVM-Specific DA
- Why Solana Itself Cannot Be Used as DA
- Challenges of Using SVM-Based Instances as DA
- Developing Data Verification Methods for DA
- Potential Solutions Explored by Yona Labs for Implementing Native SVM DA Solutions
- Conclusion
1. Introduction: The Growing Need for DA Layers for Solana
In this article, researchers from Yona Labs address the use of DA for Solana itself as an L1, for SVM-based L2s, and the challenges of using Solana as a DA layer despite its impressive performance. For projects in the EVM ecosystem, there are many native DA solutions that address various issues, such as data verification through DAC or simple data storage to avoid overloading the chain.
The problem of data availability concerns how blockchain network participants can ensure that all data for a new proposed block is genuinely accessible. If the data is unavailable, the block may contain malicious transactions hidden by the block producer. Even if the block does not contain malicious transactions, concealing data could compromise system security, as no one else can verify the chain's state.
In the context of Solana itself, the relevance of using DA has emerged due to the increasing load on the Solana blockchain as Solana and its ecosystem grow, which also increases the blockchain's size and, consequently, the storage requirements for validators. Furthermore, the larger the blockchain size, the longer it takes for new nodes to bootstrap.
In the context of SVM L2s, this is driven by the fact that as Solana and its various environments evolve, modular architecture becomes increasingly significant. These modules need to be lightweight, scalable, and compatible with other systems to avoid overburdening Solana’s core infrastructure. However, the absence of a reliable DA layer adapted for SVM presents substantial challenges, particularly as Solana, SVM L2s, and various modules for them continue to expand.
DA facilitates operations by ensuring that all data required to validate and execute transactions is available. In a blockchain, the DA layer is responsible for storing and providing the following types of data:
- Transaction data (e.g., parameters, addresses, execution states)
- Block data (e.g., metadata and transaction bodies)
- Network state data (e.g., balances, smart contract states)
- Encoded backup data to ensure reliability
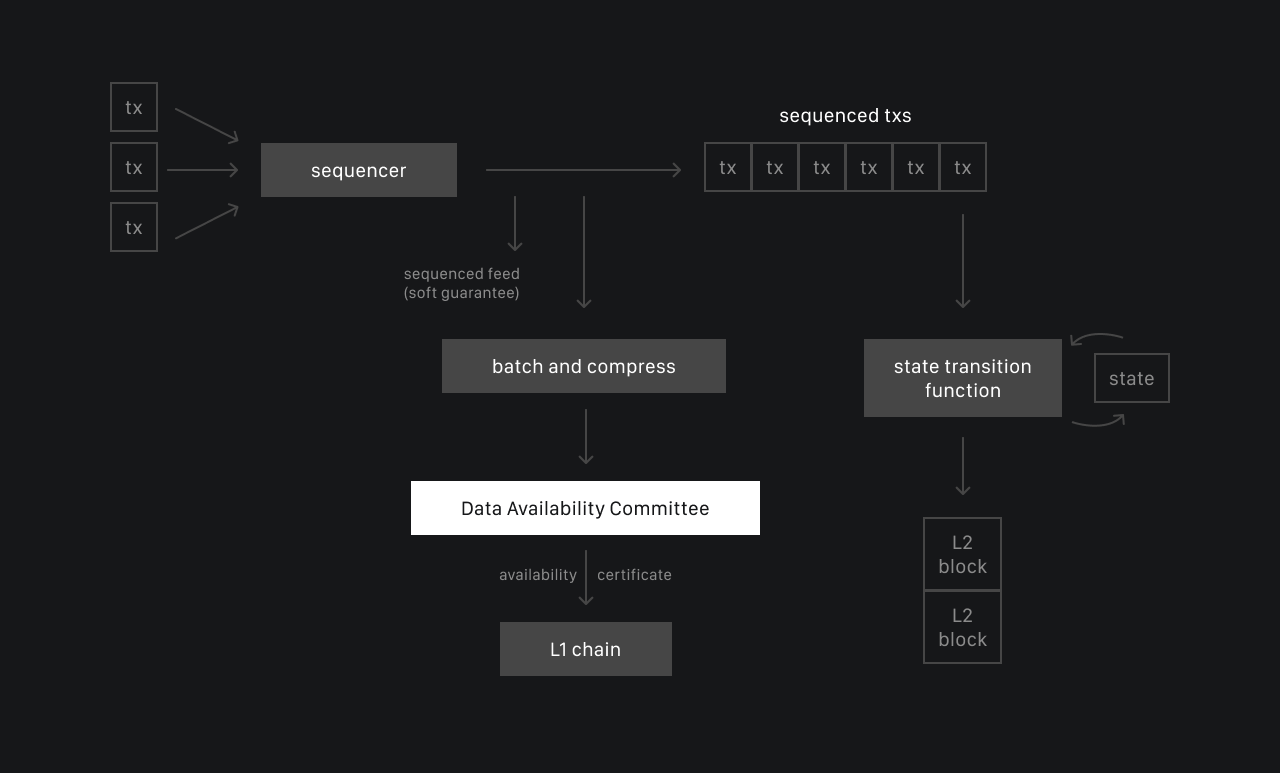
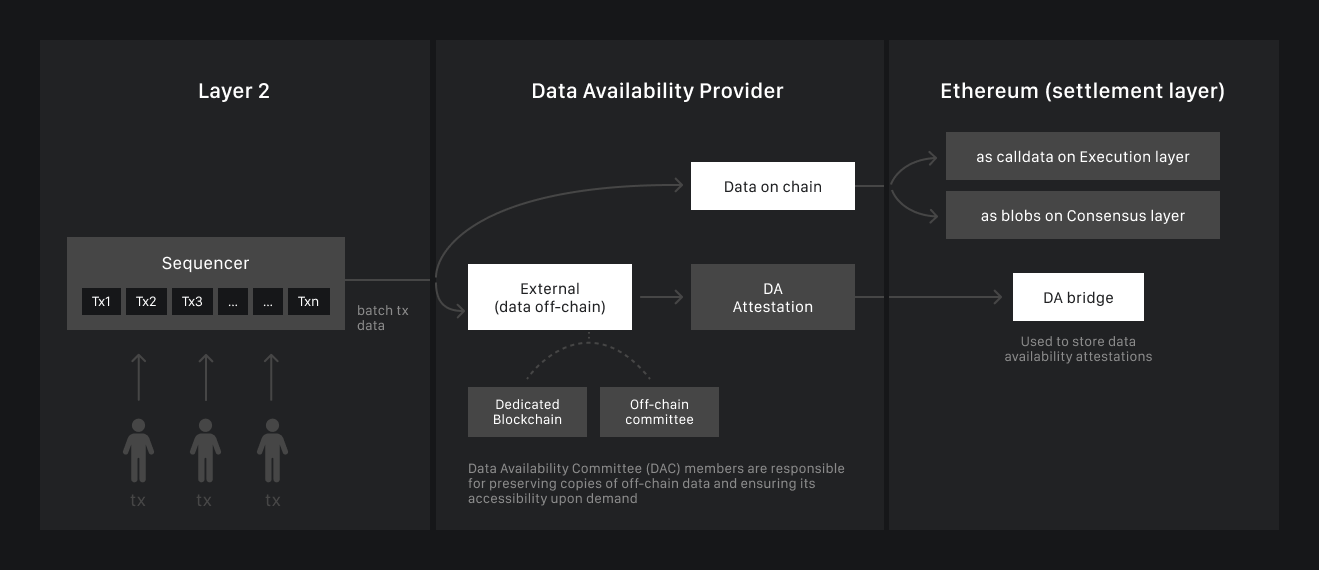
These challenges have been effectively addressed in the EVM ecosystem through modular DA frameworks such as Celestia and Avail. These platforms support not only EVM but also other virtual machines, including SVM and CosmWasm. At the same time, Solana lacks a native DA layer, forcing developers to seek external solutions, including EVM DAs. To begin, let’s examine the difficulties of using Solana itself for data availability and why EVM-based solutions are not ideal for SVM-based applications.
2. Why It’s Important to Develop an SVM-Specific DA
Firstly, SVM and EVM operate very differently. For example, EVM uses calldata to send data to Ethereum L1, ensuring both data availability and storage. Calldata in a transaction consists of hexadecimal data sent alongside the transaction, allowing messages to be delivered to other entities or interactions with smart contracts. However, calldata is limited to approximately 10 KB per block, and at a fixed cost of 16 gas/byte, it becomes very expensive. This is one of the reasons that led to the creation of DA for rollups and the introduction of EIP-4844.
In Solana, even a feature like calldata differs significantly: calldata does not require ABI encoding as it does in Ethereum, and Solana does not use 256-bit words. Additionally, unlike EVM, each instruction has its own calldata buffer, the first parameter of which is always an unsigned integer corresponding to the index of the function being called. Another example is the fact that "Wallet" accounts in Solana cannot do much directly, as all interactions are tied specifically to Programs: they can store SOL, interact with system-level programs (e.g., the System Program), and act as authorities for accounts owned by the program (linked within the program’s space). In Ethereum, funds reside directly at an address.
Thus, it becomes clear that SVM and EVM have a substantial number of differences. Consequently, DA solutions designed for EVM may act as bottlenecks for SVM rollups, as SVM’s performance is significantly higher, and the performance and throughput of a rollup heavily depend on data handling. In this scenario, the DA layer could limit performance because if it processes data slower than the sequencer generates transactions, the maximum performance will be capped by the DA layer.
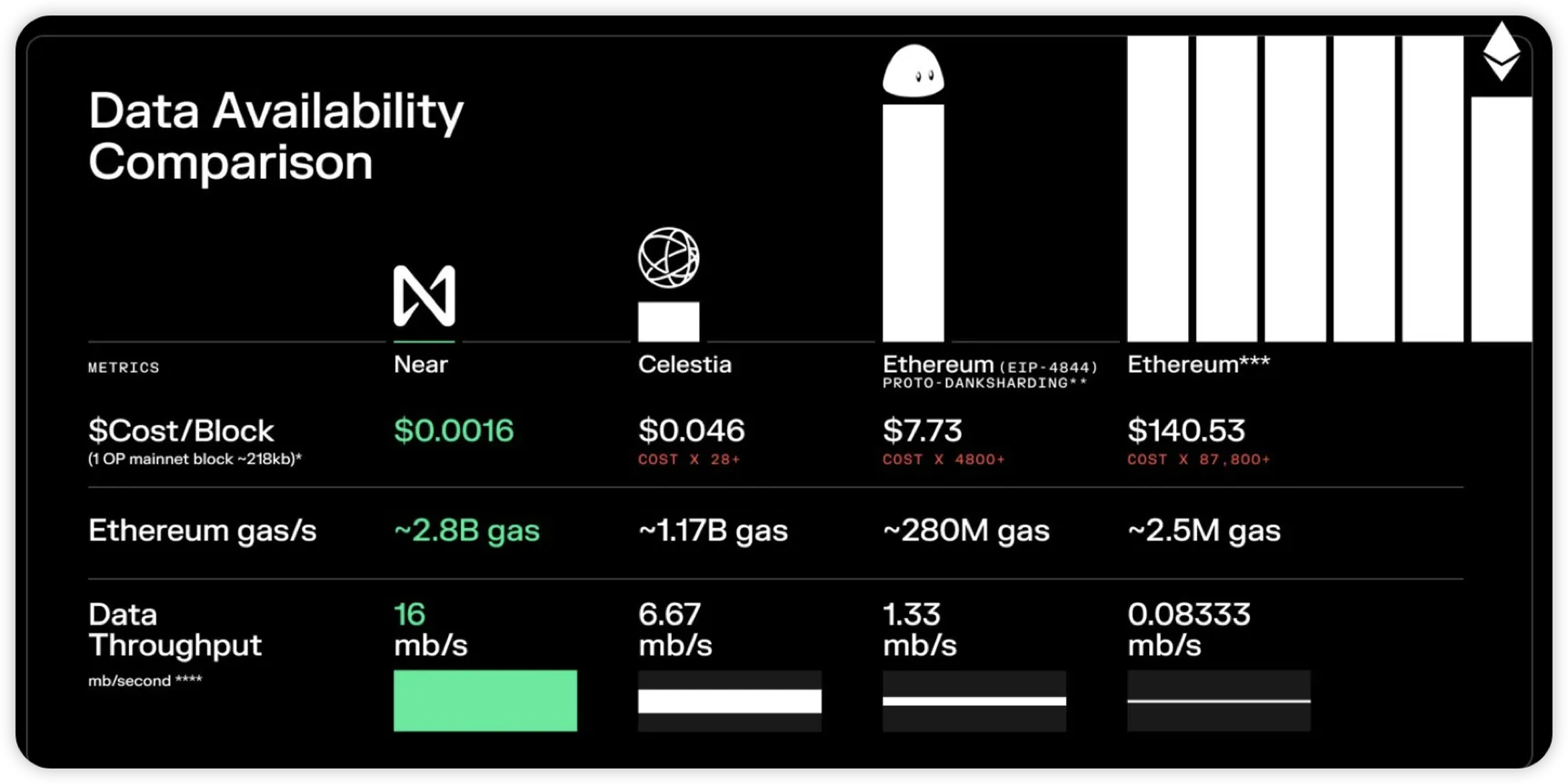
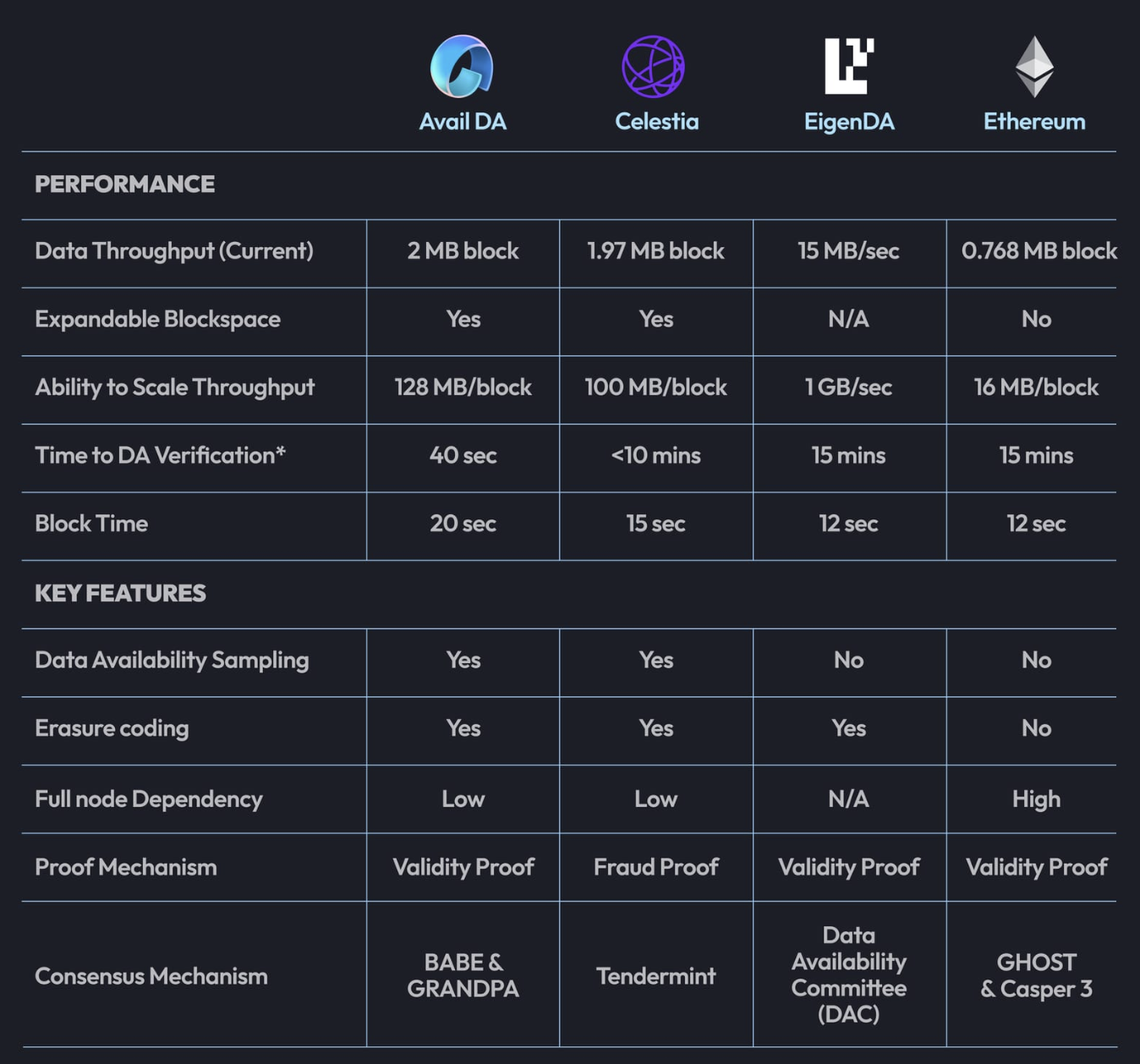
And the greater the TPS and throughput of a blockchain, the more data it generates per unit of time.
3. Why Solana Itself Cannot Be Used as DA
This scenario is the most logical and straightforward but also the most complex and inefficient. Let’s explore why.
Solana has a limited transaction size. One could attempt to split data into chunks and write each fragment into multiple transactions. However, this is an extremely inefficient process since data will be generated faster than it can be recorded, leading to massive congestion in Solana.
Another option is to use accounts. Given the maximum account size of 10 MB, this limit can be extended simply by adding more accounts. Whatever design pattern is chosen to achieve this, it is necessary to ensure consistency, make the data discoverable, and have a strict mechanism to determine who is allowed to create new accounts and when.
Considering these prerequisites and basic programming data structures, linked lists appear to be an obvious solution meeting all necessary requirements.
Accumulation would start with an initial account of 10 MB, containing the initial data and enough space to accommodate additional batches. Batchers would have the opportunity to place their batches in each account block, with each new batch assigned an ordered ID.
To allow the sequencer to scale beyond Solana’s 10 MB limit, it would be necessary to implement a linked list design pattern for accounts, further complicating this approach. Consequently, something akin to Solana account orchestration would be required to distribute tasks among these accounts, leading to even more data generation. For such a method, a compact account management mechanism would need to be developed first.
Moreover, this approach would be costly—rent must be paid to store data in accounts; otherwise, a program or account will disappear once it can no longer pay the rent. Naturally, storing large amounts of data would result in many accounts requiring rent payments, which would progressively increase.
Given the substantial amount of data on the blockchain, accounts would fill up very quickly. Deleting accounts could be an option, but state changes would still be recorded on the blockchain, again leading to the opposite effect. The goal of DA is to reduce the load, not increase it. For this reason, Yona Labs is exploring various solutions, including some unconventional ones.
4. Challenges of Using SVM-Based Instances as DA
Despite their advantages, SVM instances inherit certain characteristics from Solana when used as a DA layer:
- Architectural Features: SVM employs a unique approach to achieve high throughput and low latency, utilizing innovations like Proof of History (PoH) and the Turbine block propagation protocol. These features differ significantly from Ethereum’s architecture and its rollups, which often rely on DA layers like Celestia. Differences in consensus mechanisms and data transfer methods make direct integration of existing DA solutions into Solana’s infrastructure challenging.
- Transaction Size Limitation: The 1.2 KB limit is insufficient for storing zk-proofs or large transaction data sets. Even compact zk-proof schemes like Sonic and Plonk exceed this limit and require substantial computational resources.
- High Data Volume: DA layers must handle diverse and large data sets, such as transaction data, block data, and network state data. Solana’s architecture is not optimized for such tasks.
- Dependence on External Solutions: Some SVM rollups use Ethereum as a confirmation layer, highlighting the absence of native DA solutions within the Solana ecosystem.
- Cost: While Ethereum-based DA solutions are scalable, storing large amounts of data on Ethereum remains expensive. This raises the question of whether specialized DA solutions for Solana could be more cost-effective.
- DA as a Bottleneck: Data availability imposes limits on modern rollup systems. Even if a specific L2 sequencer were a supercomputer, TPS would ultimately depend on the throughput of the data availability layer it relies on. If the DA solution or layer used by the rollup cannot handle the volume of data the rollup’s sequencer wants to offload, the sequencer will not be able to process more transactions, no matter its capability. This is clearly illustrated in the Soon SVM framework.
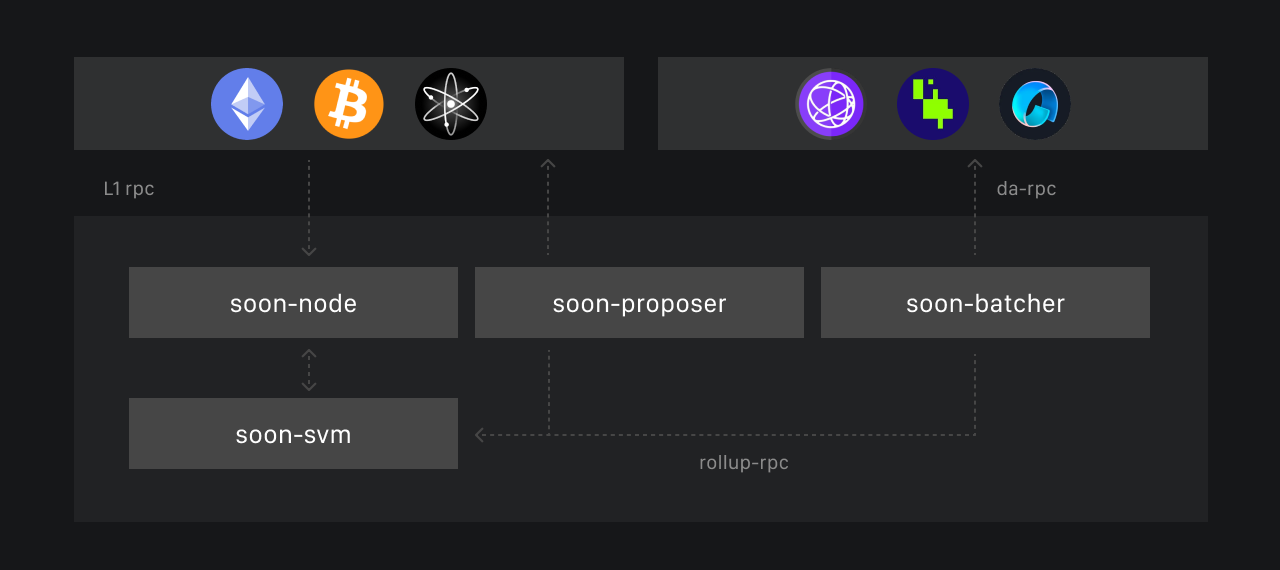
But Soon addresses this issue by introducing the Decoupled SVM structure, where the TPU (Transaction Processing Unit) is separated from Solana's consensus and controlled by the rollup node. This innovation eliminates the need for vote transactions, reducing unnecessary DA consumption and enhancing L2 efficiency.
- Trust Issues: From Ethereum’s perspective, the security assumptions of external DA providers depend not only on the internal characteristics of the DA solution itself but also on how well its security properties align with the data attestations placed on the DA bridge to Ethereum. For this reason, some projects are considering the use of Solana as a DA layer, leveraging the decentralized security provided by Solana validators. However, as discussed above, using an L1 as a DA layer is challenging because this layer requires a separate approach and optimization.
5. Developing Data Verification Methods for DA
Another crucial aspect requiring close attention is the design of DAC or DAS mechanisms. Data Availability Committee (DAC) and Data Availability Sampling (DAS) are two distinct approaches to solving the data availability problem in blockchain systems, especially when using rollups for scaling. When developing a DA solution, it is necessary to strategically choose between these two methods and evaluate how well each solution fits the SVM context.
DAC: This is a group of trusted network participants who collectively store and provide transaction data for rollups. Unlike publishing all data on the blockchain (as in Ethereum), DAC minimizes the load on the main layer by keeping data off-chain while ensuring its availability for validation. It also guarantees access to data necessary for proper state validation.
DAS: This is a decentralized method of verifying data availability by having network nodes selectively request small portions of the data.
| DAC | DAS |
|---|---|
| A trusted group of participants is responsible for the data | The data is validated by random fragment queries |
| Semi-decentralised | Fully decentralised |
| Usually cheaper, but requires trusted participants | Higher, due to coding and sampling overheads |
| Arbitrum DAC, EigenDA | Celestia, Avail DA |
| Through signatures and reputation of participants | Cryptographic proofs based on probability |
| Relatively low | High, requires implementation of complex coding algorithms |
| Collusion of participants, censorship, failure of one of the nodes | High computational burden of coding |
6. Potential Solutions Explored by Yona Labs for Implementing Native SVM DA Solutions
- Data Compression and Off-Chain Aggregation: Some developments, such as m31 by Starkware, focus on compactly packaging zk-proofs, making them suitable for storage in limited spaces like Bitcoin or Solana blocks. However, for large volumes of data, such as smart contract states, robust DA solutions remain necessary.
- EVM-Compatible DA Solutions: Integrating frameworks that ensure easy compatibility with EVM-based DA solutions, such as Celestia or Avail, could provide scalable DA solutions for SVM, bridging Solana with the EVM ecosystem.
- Hybrid Validation Models: Employing clustered Data Availability Sampling (DAS) within Solana could distribute the data validation workload among smaller groups of validators, improving scalability while maintaining decentralization.
- Launching an SVM-Oriented DA or Connector for Interpreting Solana Bytecode for EVM: This is one of Yona Labs' current focuses, exploring various DAs like Nubit, 0G, Avail, and others for practical purposes, testing their environments, and assessing compatibility with Solana bytecode. The modern web3 landscape is multi-component and modular, offering a vast array of building blocks. Thus, a solution enabling any SVM-based instance to use any DA of choice without requiring extensive development or optimization could be proposed.
- Optimization of a Modified SVM Instance: The Yona Labs team has created its own SVM instance with real-time execution. This implementation could be further optimized by increasing block and transaction capacities to accommodate more information.
- Development of DAC and DAS Solutions: When developing DA, a strategic choice between these two approaches is critical. Additionally, it is essential to evaluate how well each solution fits SVM requirements.
- Implementing a Solution Similar to Ethereum’s Blob for Solana: Ethereum’s EIP-4844 (Proto-danksharding) introduces ~2 MB (wth potential to 16mb with full dankshading) of dedicated data space per block, which can be utilized by rollups. To prevent state bloat, these BLOB data segments can be deleted after a month. This approach reduces block space usage—data throughput in proto-danksharding targets 0.375 MB/block instead of the 2mb in the current implementation and full 16 MB aimed for danksharding in future. Implementing similar technology in Solana could be a technological breakthrough, leveraging Solana’s ultra-high speed and reliability.
7. Conclusion
Using Solana as a DA layer has proven limited due to architectural constraints, challenges in data management, transaction size limitations, and significant differences between SVM and EVM technology stacks. Potential issues with scalability, storage costs, and increasing loads highlight the need for at least conceptual exploration, if not immediate development, of future SVM-oriented DA solutions.
In light of these challenges, Yona Labs proposes several potential approaches, including hybrid validation models, optimizing Solana’s architecture for dedicated environments and handling large data volumes, and conceptual design and testing of experimental DA connectors for EVM integration. These efforts have the potential to not only address current issues but also lay the foundation for a scalable and decentralized ecosystem around SVM, capable of meeting the demands of Solana’s growing world.
In addition to this, Yona Labs plans to begin a broader body of research and hands-on work with Avail to explore the possibility of directly connecting SVM-based environments with Avail's DA solution to circumvent the limitations we mentioned above in this article. With the use of DAS and fast runtime speed (40 sec for DA verification), Avail can be considered a solution suitable for SVM-based ultra-performance instances that can generate tens or hundreds of thousands of TPS. Stay tuned, more details will follow!
About Yona Network
Yona is a real-time latency Bitcoin L2 blockchain enabling Web2 experience for dApps. We use custom hyper-optimized modularized SVM to achieve superior performance with less than 10ms latency and block time. Yona enables lightning-fast transactions and offers limitless scalability, paving the way for next-generation protocols tailored to enhance the user experience within the Bitcoin ecosystem.
Yona Network links:
Website | Documentation | Twitter | Discord | Blog